Atlas login
Atlas login
by Andrey Sekste and Andrei Valasiuk
Kontur has a long history of using, developing, and maintaining free and open-source geospatial software. Open licenses help ensure that our tools are sustainable, scalable, reusable, and transparent. Free software is especially critical in the humanitarian sphere where organizations are dealing with urgent problems (such as response to natural disasters) and cannot afford delays due to funding issues and resource allocation lead times when using proprietary solutions.
Our approach to advancing the humanitarian mapping field is by growing and developing open-source solutions that the community can freely use and build upon. Among the tools we have open-sourced to a large extent (excluding certain custom functions used internally) is our data processing pipeline Geocint.
What is Geocint?
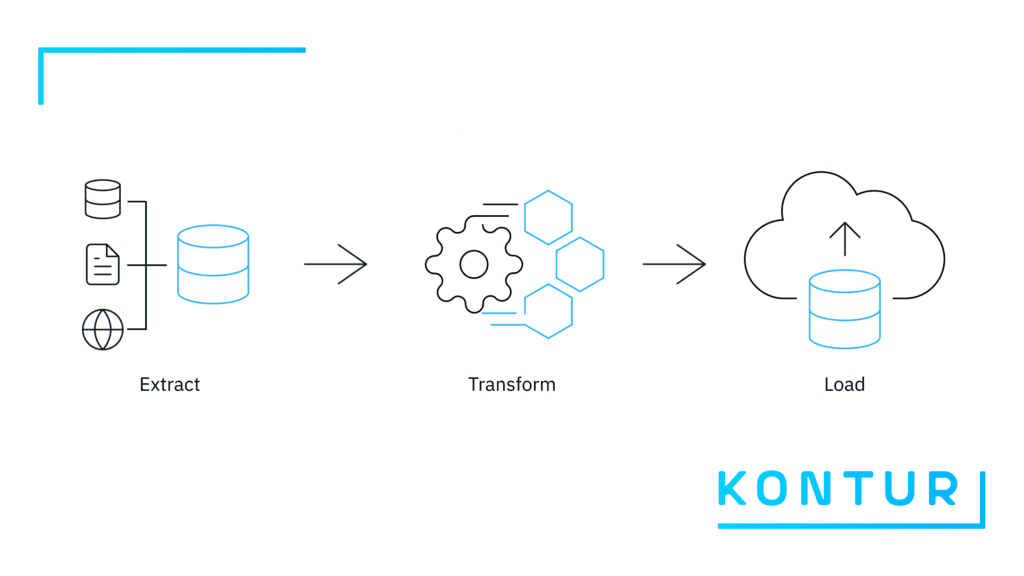
The overall amount of data, its types and sources is continuously growing. So is the need to derive relevant insights from data via analytics. This often requires data teams to process and clean raw data until it becomes useful in addressing a particular problem, whether in the commercial, public or humanitarian fields. An Extract Transform Load (ETL) pipeline is a set of processes for extracting data from original heterogeneous sources, transforming it into a usable format, and loading it into end-user systems.
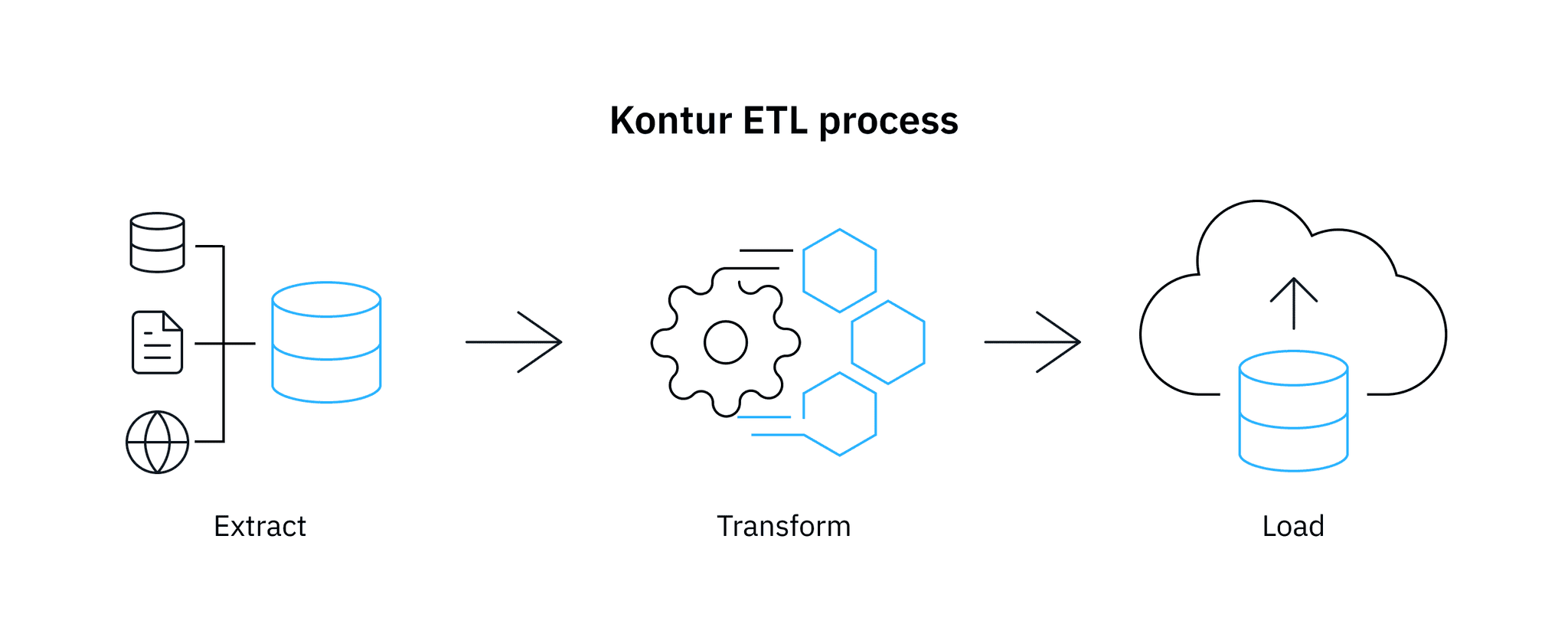
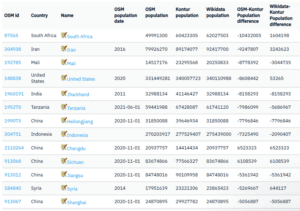
Geocint is an ETL pipeline for processing geospatial data. In general terms, it extracts data from different sources into PostgreSQL for processing, transforms it into H3 hexagons (more on that later), and loads it into the production system. At Kontur, we have been using Geocint internally for a long time – to build the Kontur Population and Kontur Boundaries datasets. We also used it to prepare data for the Disaster Ninja app before deciding to make it reusable by other organizations in the GIS field.
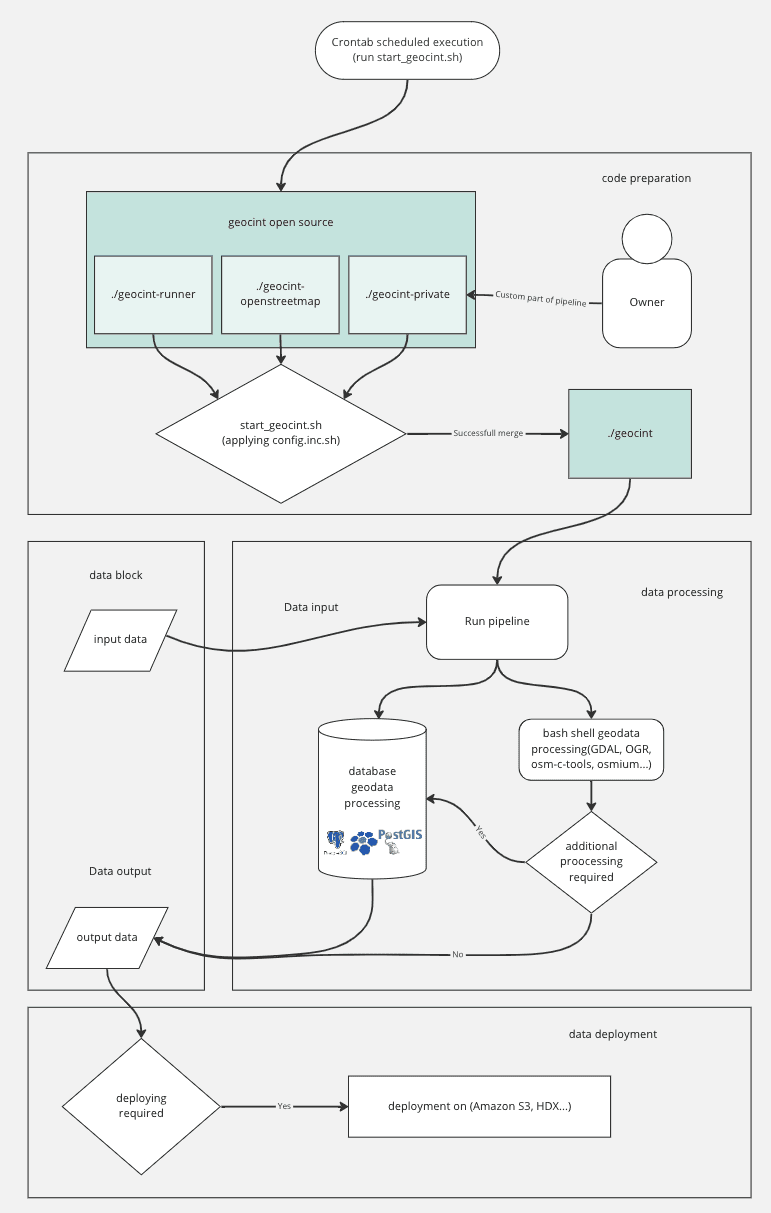
The pipeline’s code and documentation are publicly available on GitHub and distributed under the MIT license. Geocint’s technology stack is entirely open-source. It includes Bash (Linux shell) for scripting, GNU Make as a job server, PostgreSQL and PostGIS for data manipulation, h3-pg for hexagon grid manipulation, and several open-source software packages for geodata processing – among other technologies. See the pipeline’s architecture in the diagram below:
Why use it?
Many options exist when looking for tools to build a geospatial data pipeline that makes data-driven insights part of your business processes. Based on our experience and other available information, we have compared Geocint with popular ETL tools in the table below. Among the numerous general-purpose ETL solutions, we focused on open-source tools that can manage geospatial data.
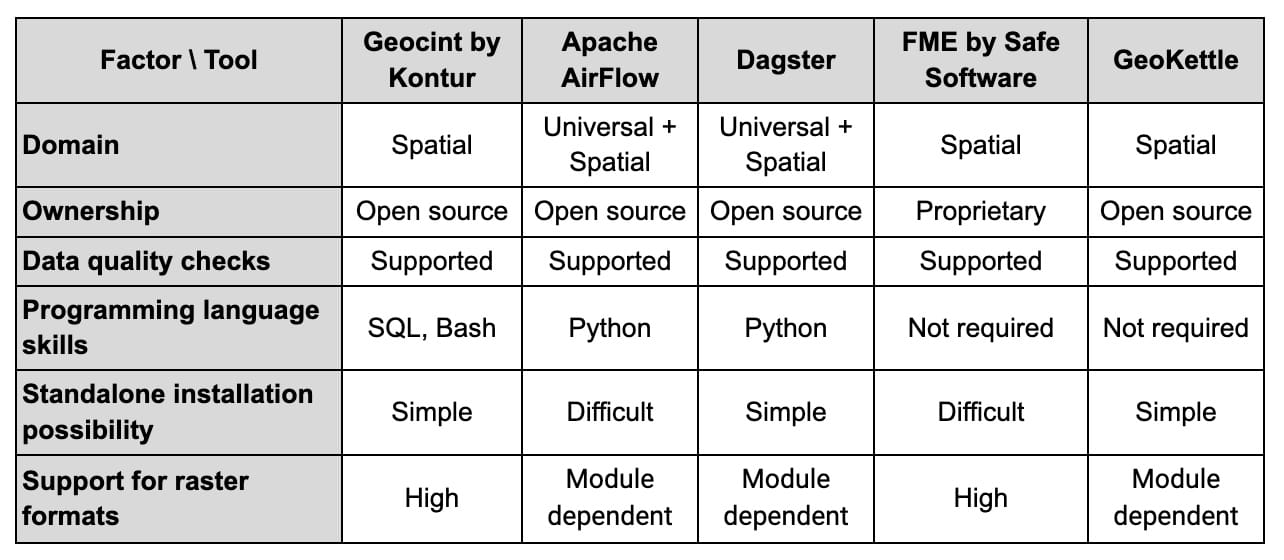
There are many ways to compare data pipeline tools, and the list of factors above for selecting the right option is certainly not exhaustive. The graphical interface and customer support are examples of other criteria to consider. Below, we outline what we see as differentiating qualities of the Geocint pipeline and the benefits it offers to users.
Clear dependencies
When your pipeline is relatively small, it can be as simple as a bash script, a set of commands in a plain text file that generates data. As time goes on, it often becomes complex to track the commands’ sequential order and to be able to recollect them in a clean state. Geocint solves this problem by using the make tool, which makes it sufficiently simple and clear to define what should happen before and what should happen after. Make-profiler, a Makefile profiling toolset and a key component of Geocint, helps manage a large data processing pipeline written in Makefile.
Previously, when a large script failed close to the end, it required extensive work to rebuild. A system of targets (minimal blocks of our ETL process, as explained later in the post) helps avoid this problem. The system’s convenience is that you can divide the script into parts, assign them to different targets, run them, and correct the failed parts only. Geocint doesn’t require complex syntax – writing commands in the target is similar to running them in the console.
You can run it with limited programming skills
A fundamental problem related to human capital in developing geospatial pipelines is that software developers often need to be more proficient in geographic information systems (GIS) whereas GIS specialists need programming skills. An SQL course, however, is usually included in GIS education programs, which is why an ETL pipeline minimizing the use of other technologies will allow GIS analysts without programming experience to start working with it in a reproducible way.
Powerful and efficient
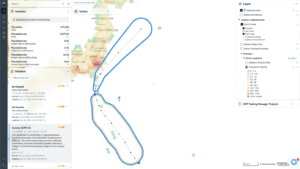
We built the Geocint pipeline around PostgreSQL, PostGIS, and h3-pg (PostgreSQL bindings for H3). The latter is a hexagonal hierarchical geospatial indexing system that partitions the world into hexagonal cells (see the image below). Thus, Geocint combines the powerful data processing features of PostgreSQL with the efficient geometric operations from PostGIS and the key benefits of using the H3 grid system, such as high-performance lookups and a compact storing format.
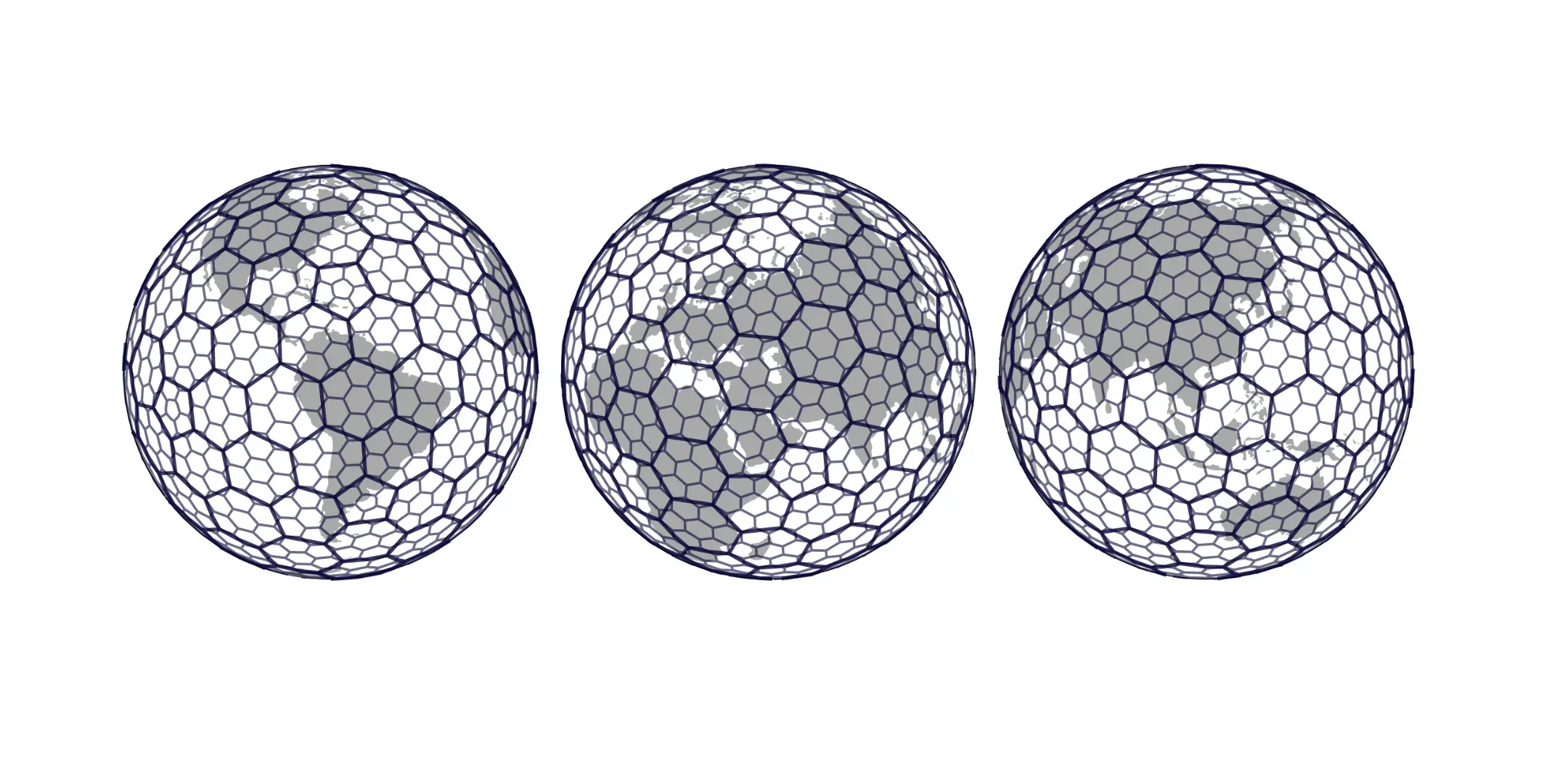
The Geocint pipeline can successfully handle large geospatial datasets with efficient parallelization mechanics. For instance, it provides a ready-made way to download a planet dump from OpenStreetMap, update it, and upload it to a PostgreSQL database. It also supports raster formats in the base configuration without requiring special modules.
Open source and requires few resources
Crucially, Geocint is a fully open-source project, meaning that all the packages we use to build it are publicly available. Furthermore, you can install it on your local server as a purely standalone instance – you only need an internet connection to install packages used in the data processing. In practical terms, the pipeline allows efficient use of PC resources: it can be run on a reasonably priced computer by a small organization.
How does it work?
Geocint consists of the following three repositories:
- open-source geocint-runner – a core part of the pipeline, which includes utilities and the initial Makefile;
- open-source geocint-openstreetmap – a chain of targets for downloading, updating, and uploading OpenStreetMap data;
- open-source or private repository with a custom Makefile that expands the Geocint pipeline with your target chains. You can see a sample Makefile here.
The latter repository and an Ubuntu server are required to install your Geocint pipeline instance. Please use a complete step-by-step installation guide here.
Once it’s running, the pipeline consists of many small “targets,” the minimal logical blocks of the ETL process. A target is a set of rules determining when and how to rebuild specific targets. It is also a set of recipes, the actual commands to be executed when creating or updating the target (see an example below). Writing the code as a Geocint target ensures that you record it entirely, you can run it autonomously, and other team members can inspect, review and test it. Besides, it will automatically produce new artifacts once new input data comes in.
db/table: | db ## Directory for storing database tables footprint
mkdir -p $@
db/table/sometable: data/in/some_table.csv | db/table ## Load data into database
psql -c "drop table if exists some_table;"
psql -c "create table some_table(name text);"
cat data/in/some_table.csv | psql -c "copy some_table from stdin;"
touch $@
A standard way of using Geocint is to run the pipeline automatically by scheduling to update the OpenStreetMap planet dump in the database and rebuild OSM-based datasets. However, Geocint allows you to manually run the whole pipeline or separate targets to rebuild only the necessary parts.
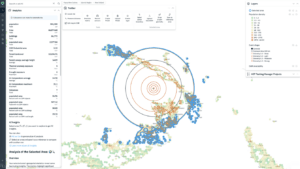
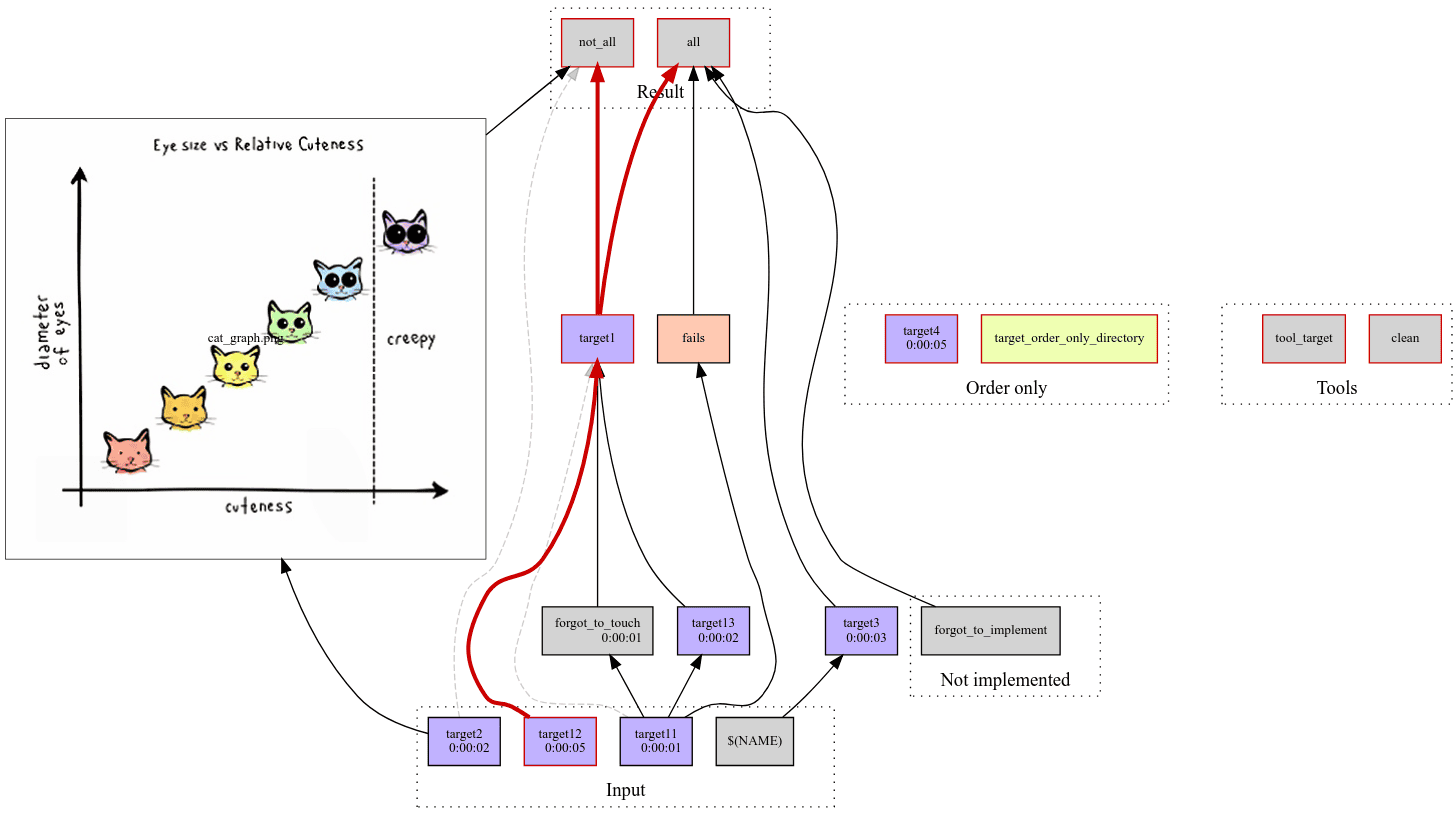
As for managing the pipeline, the make-profiler tool produces a network diagram displaying everything that is getting built, when, and why. The output chart (see an example below) lets you know what went wrong and quickly get to the logs. We are also currently working on the functionality of building HTML reports tracking pipeline execution progress.
Finally, the Geocint pipeline is easy to integrate with Slack so that it sends automatically generated messages about its progress, errors, and other information to a dedicated Slack channel.
Where can you apply it?
For data-driven organizations, it is critical to have reliable ETL processes. As an open-source tool, Geocint can help organizations and individuals who work with geospatial data and need to process it efficiently. At Kontur, we use Geocint to serve data for Disaster Ninja, a critical event management solution with Humanitarian OpenStreetMap Team (HOT) among the end users.
Even though you can run Geocint independently, we continue developing the data processing pipeline and are happy to customize it for your needs. We have experience in packing Geocint-based pipelines and moving them to production environments.
Try Geocint right now by following the installation instructions and deployment best practices in this GitHub repository, and contact us at hello@kontur.io if you have any questions or need assistance. Please also feel free to share your experience using Kontur’s datasets and open-source solutions. Together we can make them better!